· Uncategorized · 9 min read
开源工作流引擎Prefect介绍之关键概念
本文介绍了Prefect工作流引擎,这是一个开源的Python工具,用于简化和自动化数据工程和数据科学任务的编排和调度。通过Prefect,用户可以以声明式的方式定义工作流,处理任务之间的依赖关系,并确保任务的顺序和并发执行。文章探讨了Prefect的关键特性,包括任务编排、可视化界面、跨平台支持、弹性调度和扩展性。Prefect为用户提供了灵活、可靠和可扩展的解决方案,帮助他们更好地管理和编排复杂的数据处理流程。

概念
Prefect是一个开源的Python工作流引擎,旨在简化和自动化数据工程和数据科学任务的编排和调度。它提供了一个易于使用的工作流定义和管理框架,使用户能够构建复杂的工作流程,处理依赖关系,并确保任务的顺序和并发执行。
下面是Prefect的一些关键特性:
声明式定义:Prefect允许您以声明式的方式定义工作流。您可以使用Python编写工作流代码,并以自然语言的方式描述任务之间的依赖关系。这样,您可以将精力集中在定义任务和流程逻辑上,而无需关注底层调度和执行细节。
任务编排:Prefect提供了丰富的任务编排功能,可以灵活地定义任务之间的依赖关系和运行顺序。您可以使用简单的装饰器来定义任务,以及任务之间的依赖关系。Prefect将自动处理任务的并发性和顺序执行,确保任务按正确的顺序运行。
可视化界面:Prefect提供了一个直观的Web界面,用于可视化工作流的结构和执行情况。您可以通过界面查看工作流的整体结构,监控任务的运行状态和历史记录,并在需要时进行干预和调整。
跨平台支持:Prefect可以在多种执行环境中运行,包括本地机器、云服务和容器。它与各种基础设施和工具集成,如Docker、Kubernetes、Airflow等,使您能够在不同的环境中灵活地部署和执行工作流。
弹性调度:Prefect提供了弹性调度功能,可以根据任务的资源需求和优先级,动态地分配和管理计算资源。它可以自动扩展和缩减计算资源,确保任务能够在适当的时间和地点运行。
强大的扩展性:Prefect具有丰富的插件和扩展机制,可以根据需要进行自定义和扩展。您可以编写自己的任务和调度器,以满足特定的需求,并与其他工具和服务进行集成。
总的来说,Prefect是一个功能强大、易于使用的工作流引擎,可以帮助您更好地管理和编排数据工程和数据科学任务。无论是处理大规模数据管道还是构建复杂的数据处理流程,Prefect都能为您提供灵活、可靠和可扩展的解决方案。
Flows
简单地讲,它就是一个python中的方法。Flow用来承载业务逻辑,帮助用户与流程进行交互和写作的一个容器。使用@flow装饰器表示方法。有如下优点:捕捉State transitions;校验输入;失败重试;超时控制;日志捕捉。Flow调用task,task之间不能互相调用,flow之间可以互相调用(subflow概念)。
from prefect import flow, task
@task
def print_hello(name):
print(f"Hello {name}!")
@flow(name="Hello Flow")
def hello_world(name="world"):
print_hello(name)设置(参数):
description:可选
name:可选
retries:可选,失败重试次数
retry_delay_seconds:重试延迟
flow_run_name:引擎注册名称
task_runner:默认采用ConcurrentTaskRunner
timeout_seconds:超时设置
validate_parameters:是否校验
version:版本
组合(subflow):
Flow内可调用其他flow,这时候被调用的flow是subflow或者childflow,当subflow被调用时,会创建一个新的task runner。subflow会阻塞parentflow的运行。当然也可以并行运行,参考AnyIO task groups 或者asyncio.gather这些异步方式。
Tasks
如果task之间互相调用,务必采用如下方式:task.fn(),此种调用不被推荐,会缺失掉很多系统支持比如:重试,日志追踪等。
from prefect import flow, task
@task
def my_first_task(msg):
print(f"Hello, {msg}")
@task
def my_second_task(msg):
my_first_task.fn(msg)
@flow
def my_flow():
my_second_task("Trillian")设置(参数):
name:可选
description:可选
tags:可选,方便后台管理界面进行过滤查询
cache_key_fn:上下文缓存
cache_expiration:上下文缓存时间
task_run_name:模版名称,可使用变量或者其他方法(返回string)
retries:
retry_delay_seconds:
version:
Caching:使用caching可以利用其他任务的计算结果以提高效率(输入参数相同的情况,对task设计要求较高,同时要求尽可能解藕同时合理控制task的粒度)
Results
处理task和flow的返回值。当直接调用flow或者task时,result用来接受返回值。
result可接受异步处理结果。
result也可进行持久化。当运行工作流时,Prefect会保存所有task和flow的结果(默认在内存中)以方便传给下游,这时当对象过大时,需要进行相应持久化。
Artifacts
Artifacts(数据样例)可以把flow运行的结果通过多种形式进行持久化并输出,形式包括tables,files 或者links。通过artifacts可以方便的管理和共享信息。
使用场景:Debugging;Data quality checks;Documentation
States
我们从States中可以得知哪些信息呢?
- task被调度的次数
- task是否成功和结果
- task运行状态(运行or取消)
- task使用的缓存结果
- task失败的原因
状态类型(表示结果)
- Completed
- Cancelled
- Failed
- Crashed
状态类型(表示过程)
- Scheduled
- Late
- AwaitingRetry
- Pending
- Running
- Retrying
- Paused
- Cancelling
返回值类型
- Data python对象
- State flow或者task的状态
- PrefectFuture 同时包含Data和State
Blocks
使用Block能完成与外部系统之间的交互。其中包括AWS,GitHub,Slack等。
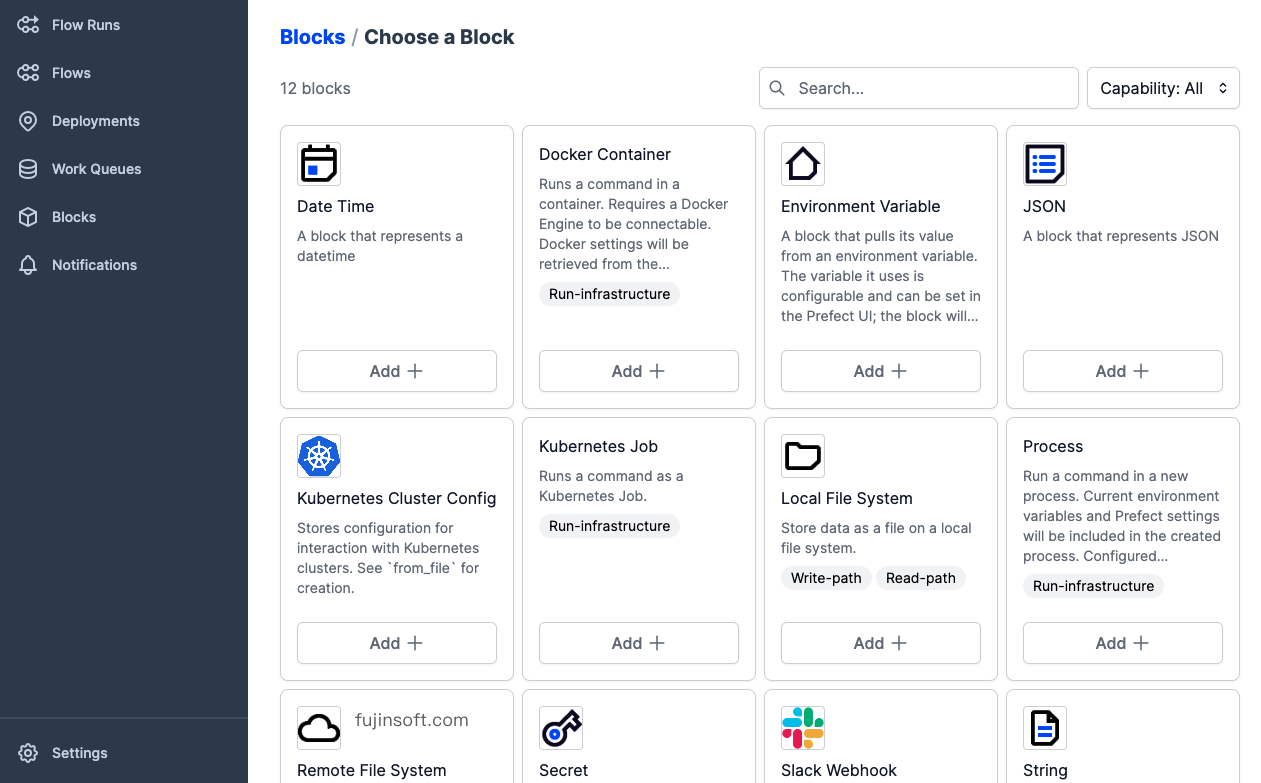
也可以按照规范自定义新的block类型。
Variables
Variables允许存储和重用数据,包括配置信息等。可以理解成环境变量。
Task Runners
Prefect提供多种默认的task runner供选择,可以根据自己的需求选择不同的runner,其中包括concurrent, parallel, distributed等。通过调用task.submit()向任务运行器task runner提交一个任务并返回PrefectFuture。
内置的task runners:
SequentialTaskRunner 顺序执行
ConcurrentTaskRunner 并发执行,任务会通过anyio被提交到thread pool
DaskTaskRunner 使用dask.distributed分布式并行执行
RayTaskRunner 使用Ray分布式并行执行
from prefect import flow, task from prefect.task_runners import ConcurrentTaskRunner import time
@task def stop_at_floor(floor): print(f”elevator moving to floor {floor}”) time.sleep(floor) print(f”elevator stops on floor {floor}”)
@flow(task_runner=ConcurrentTaskRunner()) def elevator(): for floor in range(10, 0, -1): stop_at_floor.submit(floor)
flow和subflow的task ruanner之间可以不同。
Runtime Context
使用runtime context可以查看当前flow或者task等当前prefect引擎下的对象内部信息。
from prefect import flow, task
import prefect.runtime
@flow(log_prints=True)
def my_flow(x):
print("My name is", prefect.runtime.flow_run.name)
print("I belong to deployment", prefect.runtime.deployment.name)
my_task(2)
@task
def my_task(y):
print("My name is", prefect.runtime.task_run.name)
print("Flow run parameters:", prefect.runtime.flow_run.parameters)
my_flow(1)Profiles & Configuration
通过修改Prefect引擎的默认设置,可以定制其运行的特点。支持命令行和Prefect自带的后台管理进行修改。
可设置的参数包括:
- PREFECT_API_URL
- PREFECT_API_KEY
- PREFECT_HOME
- PREFECT_LOCAL_STORAGE_PATH
- Database settings
- Logging settings